【查看网络 IP 和网关】
(1)查看虚拟网络编辑器

(2)修改 ip 地址

(3)查看网关
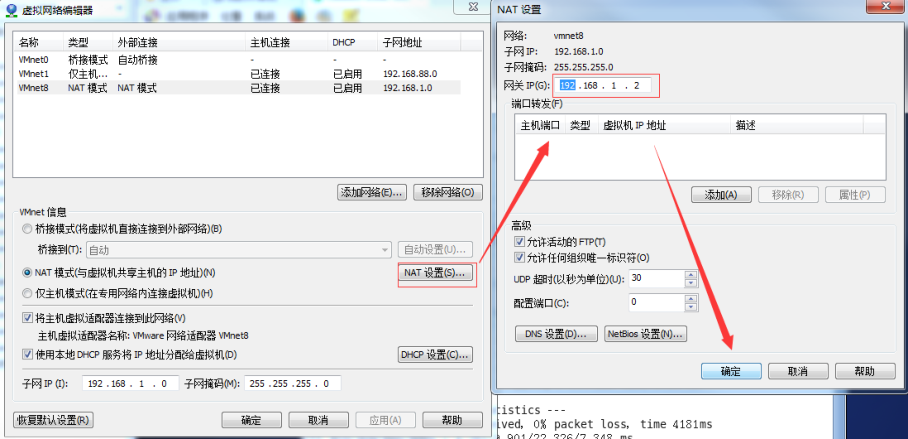
(4)查看 windows 环境的中 VMnet8 网络配置

【配置网络IP地址】
(1)ifconfig 配置网络接口
ifconfig :network interfaces configuring 网络接口配置
1)基本语法
ifconfig (功能描述:显示所有网络接口的配置信息)
2)案例实操
--查看当前网络 ip
[root@hadoop100 桌面]# ifconfig
【ping 测试主机之间网络连通性】
(1)基本语法:
ping 目的主机 (功能描述: 测试当前服务器是否可以连接目的主机 )
(2)案例实操:
1)测试当前服务器是否可以连接百度 [root@hadoop100 桌面]# ping www.baidu.com
【修改IP地址】
(1)修改IP地址
[root@hadoop100 桌面]#vim /etc/sysconfig/network-scripts/ifcfg-eth0

以下标红的项必须修改,有值的按照下面的值修改,没有该项的要增加。


修改后

:wq 保存退出
(2)执行 service network restart

(3)如果报错,reboot,重启虚拟机
【配置主机名】
【hostname 显示和设置系统的主机名称】
(1)基本语法:
hostname (功能描述:查看当前服务器的主机名称) (2)案例实操:1)查看当前服务器主机名称 [root@hadoop100 桌面]# hostname【修改主机名称】
1.修改 linux 的主机映射文件(hosts 文件)
(1)进入 Linux 系统查看本机的主机名。通过 hostname 命令查看
[root@hadoop100 桌面]# hostname hadoop100 (2)如果感觉此主机名不合适,我们可以进行修改。通过编辑/etc/sysconfig/network 文件 [root@hadoop100 桌面]# vi /etc/sysconfig/network 文件中内容 NETWORKING=yes NETWORKING_IPV6=no HOSTNAME= hadoop100 注意:主机名称不要有“_”下划线
(3)打开此文件后,可以看到主机名。修改此主机名为我们想要修改的主机名hadoop100。
(4)保存退出。 (5)打开/etc/hosts[root@hadoop100 桌面]# vim /etc/hosts
添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101192.168.1.102 hadoop102192.168.1.103 hadoop103192.168.1.104 hadoop104192.168.1.105 hadoop105192.168.1.106 hadoop106192.168.1.107 hadoop107192.168.1.108 hadoop108
(6)并重启设备,重启后,查看主机名,已经修改成功
2.修改 window7 的主机映射文件(hosts 文件)
(1)进入 C:\Windows\System32\drivers\etc 路径
(2)打开 hosts 文件并添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101192.168.1.102 hadoop102192.168.1.103 hadoop103192.168.1.104 hadoop104192.168.1.105 hadoop105192.168.1.106 hadoop106192.168.1.107 hadoop107192.168.1.108 hadoop108
3.修改 window10 的主机映射文件(hosts 文件)
(1)进入 C:\Windows\System32\drivers\etc 路径
(2)拷贝 hosts 文件到桌面
(3)打开桌面 hosts 文件并添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101192.168.1.102 hadoop102192.168.1.103 hadoop103192.168.1.104 hadoop104192.168.1.105 hadoop105192.168.1.106 hadoop106192.168.1.107 hadoop107192.168.1.108 hadoop108
(4)将桌面 hosts 文件覆盖 C:\Windows\System32\drivers\etc 路径 hosts 文件
【关闭防火墙】
【service 后台服务管理】
1)基本语法:
service 服务名 start (功能描述:开启服务)service 服务名 stop (功能描述:关闭服务)service 服务名 restart (功能描述:重新启动服务)
service 服务名 status (功能描述:查看服务状态)
2)经验技巧
查看服务的方法:/etc/init.d/服务名[root@hadoop100 init.d]# pwd/etc/init.d[root@hadoop100 init.d]# ls -al
3)案例实操
(1)查看网络服务的状态[root@hadoop100 桌面]#service network status (2)停止网络服务[root@hadoop100 桌面]#service network stop (3)启动网络服务[root@hadoop100 桌面]#service network start (4)重启网络服务[root@hadoop100 桌面]#service network restart (5)查看系统中所有的后台服务[root@hadoop100 桌面]#service --status-all
【chkconfig 设置后台服务的自启配置】
1)基本语法:
chkconfig (功能描述:查看所有服务器自启配置)chkconfig 服务名 off (功能描述:关掉指定服务的自动启动)chkconfig 服务名 on (功能描述:开启指定服务的自动启动)chkconfig 服务名 --list (功能描述:查看服务开机启动状态)
2)案例实操
(1)关闭iptables服务的自动启动[root@hadoop100 桌面]#chkconfig iptables off(2)开启iptables服务的自动启动[root@hadoop100 桌面]#chkconfig iptables on
【进程运行级别】

查看默认级别: vi /etc/inittab
Linux系统有7种运行级别(runlevel):常用的是级别3和5
• 运行级别0:系统停机状态,系统默认运行级别不能设为0,否则不能正常启动• 运行级别1:单用户工作状态,root权限,用于系统维护,禁止远程登陆• 运行级别2:多用户状态(没有NFS),不支持网络• 运行级别3:完全的多用户状态(有NFS),登陆后进入控制台命令行模式• 运行级别4:系统未使用,保留• 运行级别5:X11控制台,登陆后进入图形GUI模式• 运行级别6:系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动
【关闭防火墙】
1)临时关闭防火墙:
(1)查看防火墙状态[root@hadoop100 桌面]# service iptables status(2)临时关闭防火墙[root@hadoop100 桌面]# service iptables stop
2)开机启动时关闭防火墙
(1)查看防火墙开机启动状态[root@hadoop100 桌面]#chkconfig iptables --list(2)设置开机时关闭防火墙[root@hadoop100 桌面]#chkconfig iptables off
【关机重启命令】
在 linux 领域内大多用在服务器上,很少遇到关机的操作。毕竟服务器上跑一个服务是永无止境的,除非特殊情况下,不得已才会关机。
正确的关机流程为:sync > shutdown > reboot > halt
1)基本语法:
(1)sync (功能描述:将数据由内存同步到硬盘中)(2)halt (功能描述:关闭系统,等同于 shutdown -h now 和 poweroff)
(3)reboot (功能描述:就是重启,等同于 shutdown -r now)(4)shutdown [选项] 时间
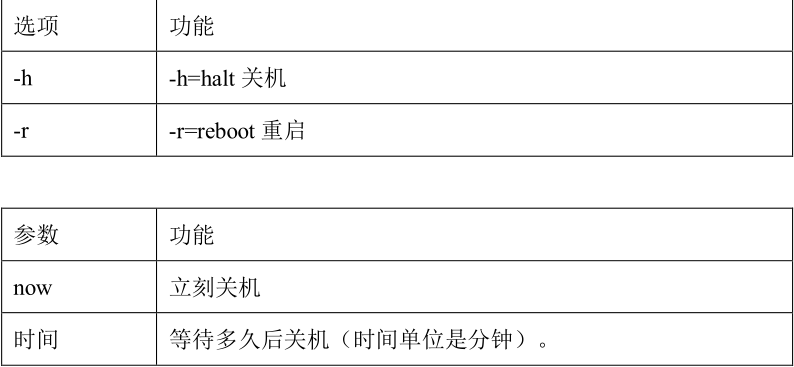
2)经验技巧:
Linux 系统中为了提高磁盘的读写效率,对磁盘采取了 “预读迟写”操作方式。当用户保存文件时,Linux 核心并不一定立即将保存数据写入物理磁盘中,而是将数据保存在缓冲区中,等缓冲区满时再写入磁盘,这种方式可以极大的提高磁盘写入数据的效率。但是,也带来了安全隐患,如果数据还未写入磁盘时,系统掉电或者其他严重问题出现,则将导致数据丢失。使用 sync 指令可以立即将缓冲区的数据写入磁盘。
3)案例实操:
(1)将数据由内存同步到硬盘中[root@hadoop100 桌面]#sync(2)重启[root@hadoop100 桌面]# reboot(3)关机[root@hadoop100 桌面]#halt(4)计算机将在 1 分钟后关机,并且会显示在登录用户的当前屏幕中[root@hadoop100 桌面]#shutdown -h 1 ‘This server will shutdown after 1 mins’(5)立马关机(等同于 halt)[root@hadoop100 桌面]# shutdown -h now
(6)系统立马重启(等同于 reboot)[root@hadoop100 桌面]# shutdown -r now
【克隆虚拟机】
1)关闭要被克隆的虚拟机
2)找到克隆选项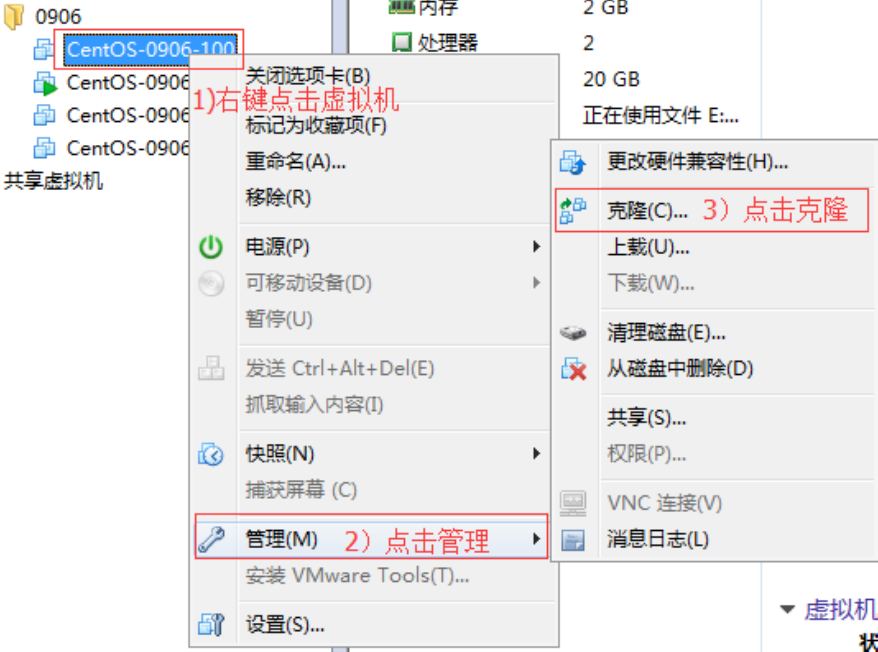
3)欢迎页面
4)克隆虚拟机
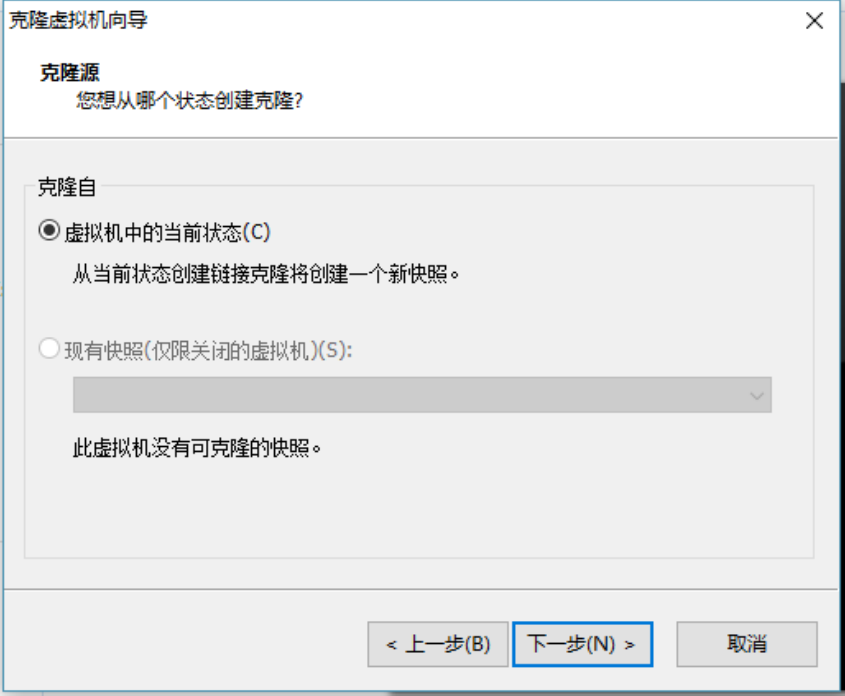
5)设置创建完整克隆

6)设置克隆的虚拟机名称和存储位置
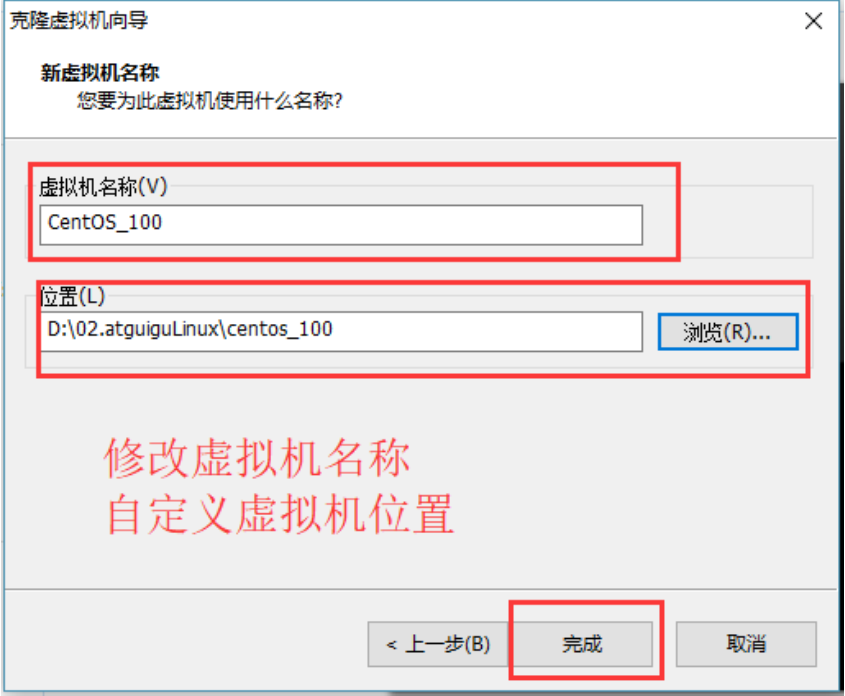
7)等待正在克隆
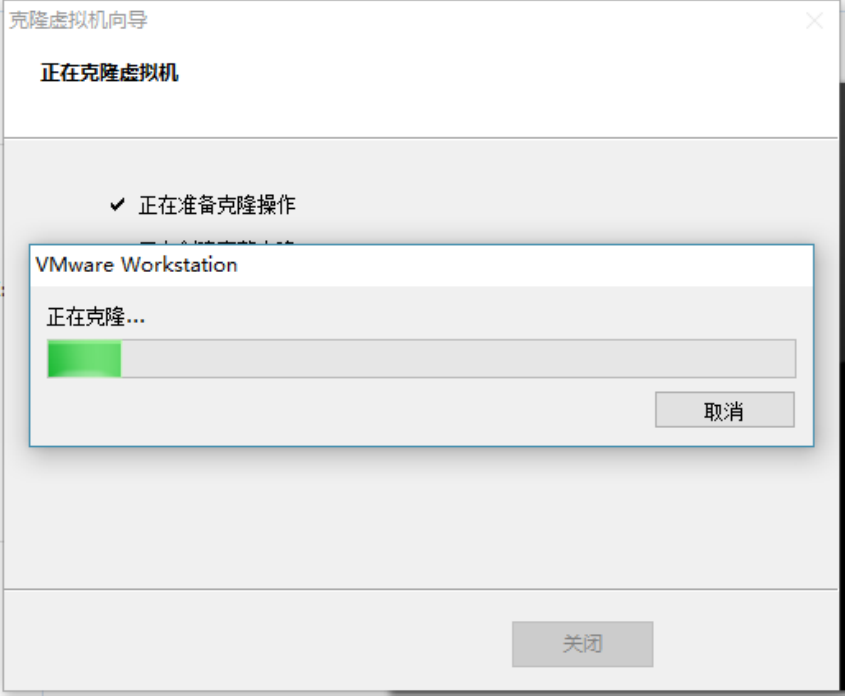
8)点击关闭,完成克隆

9)修改克隆后虚拟机的 ip
[root@hadoop101 /]#vim /etc/udev/rules.d/70-persistent-net.rules进入如下页面,删除 eth0 该行;将 eth1 修改为 eth0,同时复制物理 ip 地址
10)修改 IP 地址
[root@hadoop101 /]#vim /etc/sysconfig/network-scripts/ifcfg-eth0 (1)把复制的物理 ip 地址更新HWADDR=00:0C:2x:6x:0x:xx #MAC 地址 (2)修改成你想要的 ipIPADDR=192.168.1.101 #IP 地址
11)修改主机名称
12)重新启动服务器